We’ve seen several definitions of Poisson processes.
We can now generate our own point patterns, given the definition of a process.
Can we go the other way? Given a point pattern, can we estimate the intensity function that generated it?
We will cover parametric estimation of \(\lambda(t;\theta)\) in 1 dimension.
Outline
What is inference?
Deriving the Poisson process likelihood
Maximum likelihood estimation
Examples and representing uncertainty
Disclaimers, again.
I will be using R, feel free to reuse and adapt this code.
No requirement to use R, pick whatever language you are most comfortable in.
Focus on temporal point patterns here - core ideas extend to spatial processes. (I am deliberately leaving extensions for you!)
Inference for Poisson Processes
Inference is the process of using data to draw conclusions about a process beyond the realisation that you have available to you.
We have one (or more) point patterns, which are realisations from some point process.
We want to construct an intensity model for that point process.
We will consider the method of maximum likelihood in this lecture
Suggested Poster Topic
Inference for self-exciting point processes.
Bayesian inference for point process models.
Review of Maximum likelihood inferenece
We have observations \(\mathbf{x} = (x_1, \ldots, x_n)\) and an intensity function \(\lambda(t;\theta)\) which is described by some parameters \(\theta\), e.g.:
We want to pick the parameters \(\theta = \hat \theta\) which make the observed point pattern most likely.
To do that we find an expression for the probability of our observed point pattern and find the combination of parameter values that maximise that expression.
The likelihood of a dataset is the probability of observing that data set, considered as a function of the model parameters.
We want to find the parameters \(\hat \theta\) that make the observed data most probable - this will be our point estimate of the parameter value(s).
In a Poisson process there are two random components:
How many events we see within the process, \(\Pr(N(A) = n)\);
Where those events are located on our observation window \(A \subseteq S\).
We are interested in the joint probability of seeing the particular number of points that we did and observing those points in the locations they happened to appear:
How can \(\Lambda(A)\) be interpreted in terms of:
an area or volume;
an event count?
We can therefore replace \(\Pr(N = n)\) with the Poisson pmf:
\[ \frac{(\Lambda(A;\theta))^n \exp\{-\Lambda(A;\theta)\}}{n!} \prod_{i=1}^{n}\Pr(X_i = x_i | N = n).\]
Question
How can we get an expression for the probability of observing an event at any given location?
Since event locations are independent of the total number of events and proportional to the intensity on A, we can calculate the probability density function of an individual observation by scaling \(\lambda(s ; \theta)\) so that it integrates to 1 over \(A\).
We can see that this function has two components: one concerned with the number of events that we see, and the other is concerned with the location of those events on \(A\).
In this simple case, we can show that the MLE is equivalent to the method of moments estimate \(\hat \lambda = \frac{n}{|A|}\).
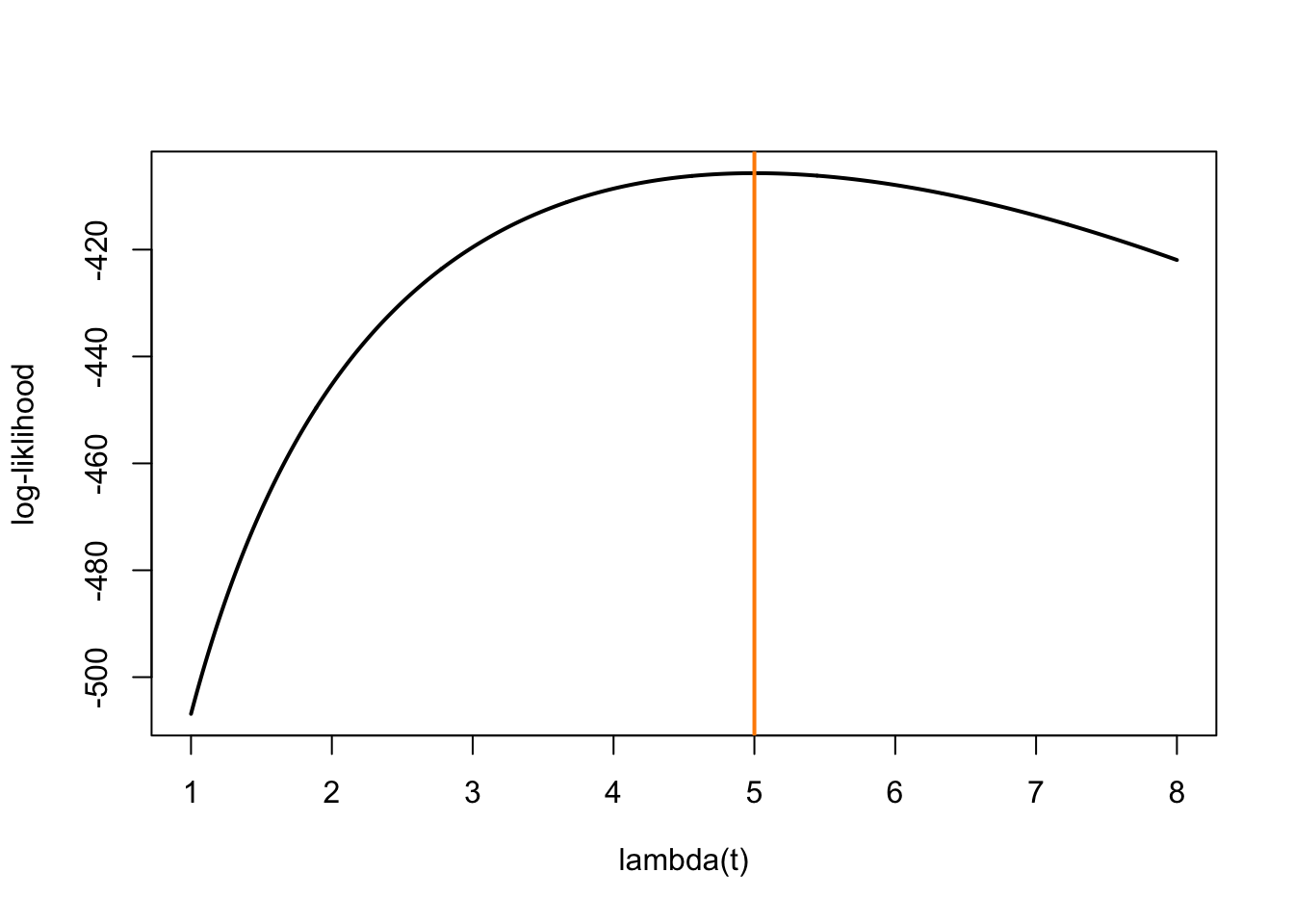
# function to calculate log-liklihoodhpp_llh <-function(lambda, n, t_min, t_max){if (lambda <0) return(-Inf) mod_A <- t_max - t_min n *log(lambda) - (lambda * mod_A) -sum(log(n:1))}# Calculate llh at a sequence of potential lambda valueslambda_values <-seq(from =1, to =8, length.out =1001)llh_values <-rep(NA, 1001)for (i in1:1001) { llh_values[i] <-hpp_llh(lambda = lambda_values[i],n =125,t_min =0,t_max =25)}# Plot log-liklihood function plot(x = lambda_values,y = llh_values,ylab ="log-liklihood",xlab =expression("lambda(t)"), type ="l",lwd =2)abline(v =5, col ="darkorange", lwd =2)
Task
Derive this result for yourself, along with a corresponding expression for an approximate 95% confidence interval for \(\lambda\).
If you are working in R, can you modify hpp_llh() to take as input a vector of lambda values and avoid this for loop?
Can you modify hpp_llh() to take the point pattern as an input, rather than the number of points?
Inhomogeneous Poisson Processes
For almost all inhomogeneous Poisson process models numerical methods will be required to evaluate \(\Lambda(A;\theta) = \int_{s\in A} \lambda(s;\theta) \mathrm{d}s\) and to optimise \(\ell(\theta; X)\).
General approach:
Write or use a function to evaluate \(\Lambda(A;\theta) = \int_{s\in A} \lambda(s;\theta) \mathrm{d}s\).
Write a function to evaluate \(\ell(\theta; X)\).
Optimise using gradient descent or some other method.
Tips:
Make use of built in optimisers unless this will be the focus of your project - optim() or optimise() in R
scipy.optimize() in Python.
{NHPoisson}{spatstat}{splancs} …
Suggested Poster Topic
Review of packages for point process analysis in R / Python.
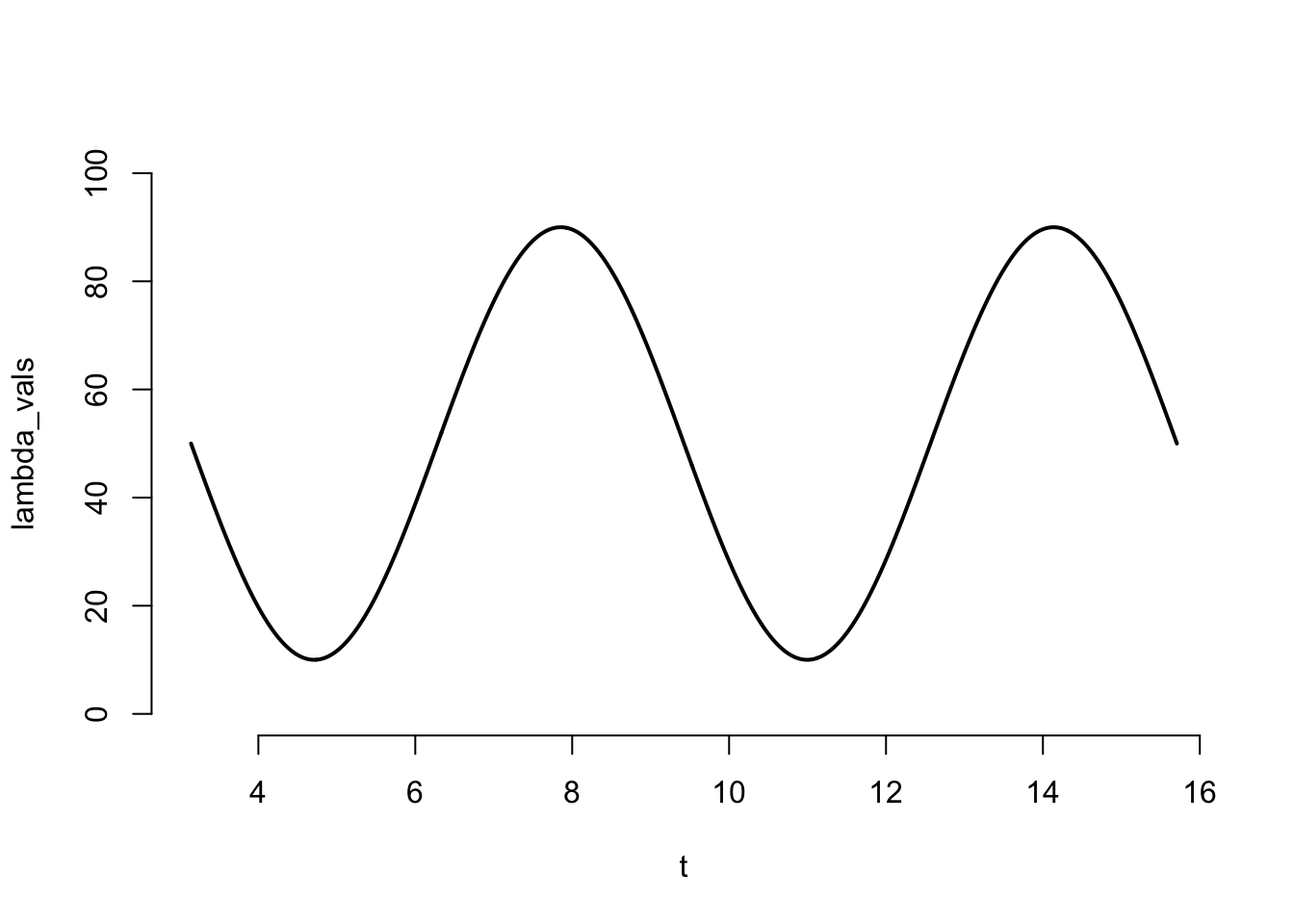
This allows us to plot the true intensity function, which is useful for checking our code / method.
# set simulation parameterst_min <- pit_max <-5* pi theta_true =c(40, 50)# Evaluate lambda on regular grid for plottingt <-seq(t_min, t_max, length.out =1001)lambda_vals <-lambda(theta = theta_true, time = t)plot(t, lambda_vals, type ="l", lwd =2, ylim =c(0,100), bty ="n")
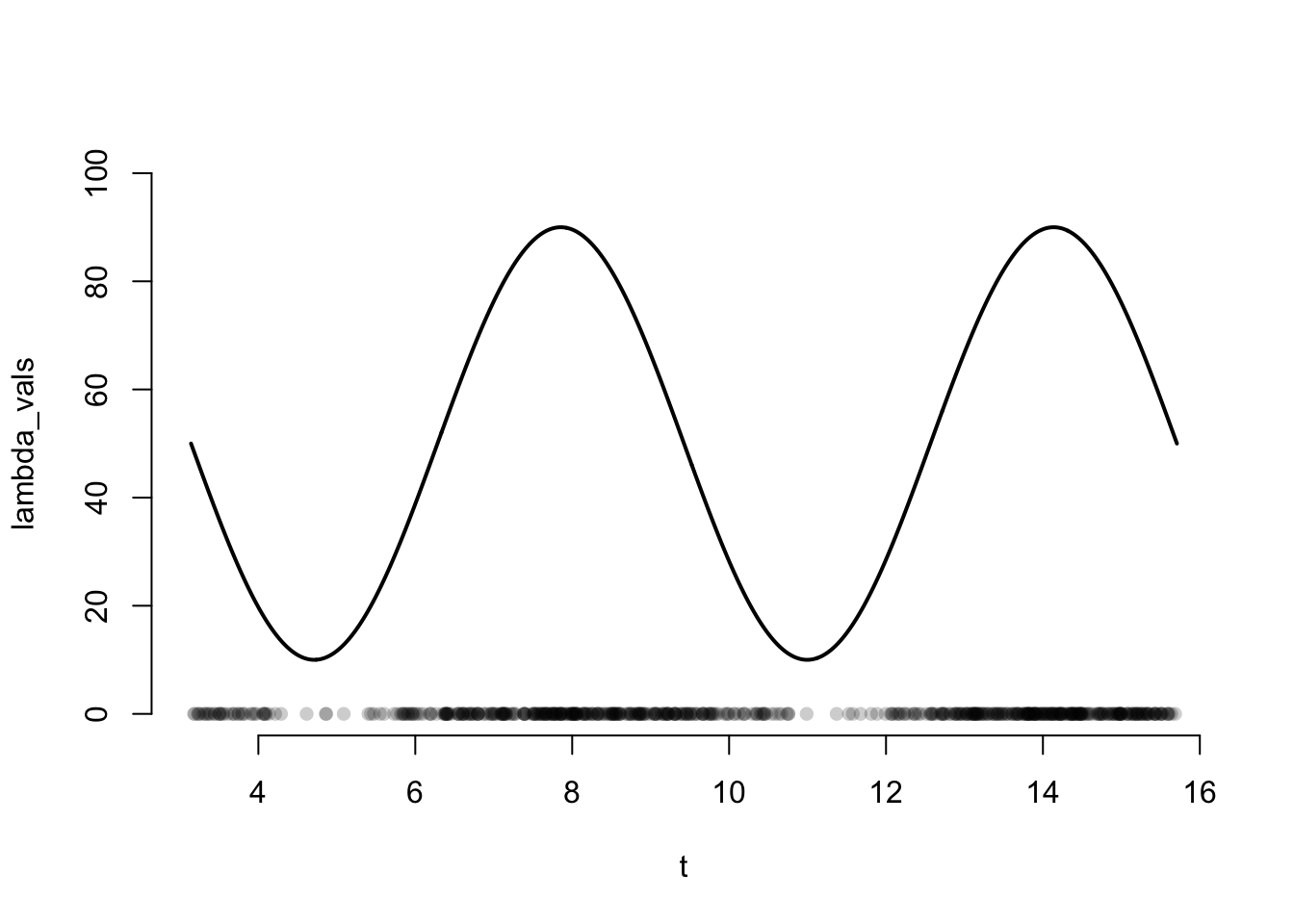
We can then simulate a point pattern from this intensity.
# Simulate a point pattern by thinning / rejection sampling# Simulate from bounding HPPset.seed(4321)lambda_max <-90n_homo <-rpois(n =1, lambda = lambda_max * (t_max - t_min))x_homo <-runif(n = n_homo, min = t_min, max = t_max)# Thin point patternprob_keep <-lambda(theta = theta_true, time = x_homo) / lambda_maxis_kept <-rbinom(n = n_homo, size =1, prob = prob_keep)x_inhomo <- x_homo[is_kept ==1]n_inhomo <-length(x_inhomo)plot(x = t, y = lambda_vals,type ="l", lwd =2,ylim =c(0,100),bty ="n") points(x = x_inhomo,y =rep(0, n_inhomo),pch =16,col =rgb(0,0,0,0.2))
Now that we have our simulated point pattern, we can try to recover the simulation parameters from it.
Note: in applications there is never a “real” parametric intensity function.
To find the MLE, we will need to write a function to evaluate the log-likelihood.
We will use R’s built-in optimiser to find the MLE. This does minimisation not maximisation.
So we need a function to evaluate the negative log-likelihood for a given set of parameters theta, point pattern x and observation interval A.
# Negative log-likelihood nllh_ihpp <-function(theta, x, A){# !! Need intensity non-negative everywhereif (theta[1] > theta[2]) return(1e8)# Integral term Lambda_term <-Lambda(theta, A[2]) -Lambda(theta, A[1])# Intensity term lambda_term <--sum(log(lambda(theta, time = x))) return(lambda_term + Lambda_term)}# Test: evaluate for lambda = 0 * sin(t) + 5nllh_ihpp( theta =c(0, 5), x = x_inhomo, A =c(pi, 5*pi))
[1] -933.4102
We can then optimise this two-parameter function using the following code, which returns a list, which gives us all the information we need.
opt <-optim(par =c(0,5), # starting parameter valuesfn = nllh_ihpp, # function we want to optimisemethod ="L-BFGS-B", # A smarter version of gradient descenthessian =TRUE, # Return numerical estimate of Hessian at MLEA =c(t_min, t_max), # Remaining parameters of lambda(t;theta)x = x_inhomo )opt
A point estimate wouldn’t be sufficient if we were estimating a scalar, and nor is it sufficient when we are estimating a function.
To visualise the uncertainty in our function we can draw lots of values for \(\hat \theta\) from it’s sampling distribution and plot the intensity function associated with each set of sampled values.
Review of Likelihood inference - part 2
The Maximum likelihood estimator has a sampling distribution that is (asymptotically) Gaussian:
If we have a large enough data set (and some mild regularity conditions hold), we can use this as result to approximate the error we make when estimating \(\theta\):
In fact, this observed information matrix is equivalent to the negative of the Hessian matrix and this is exactly what R has numerically approximated for us.
(Recall that this Hessian matrix is just a square matrix filled with second ordered partial derivatives of our likelihood function. We evaluate these partial derivatives at the maximum likelihood estimate to describe the local curvature of the likelihood function.)
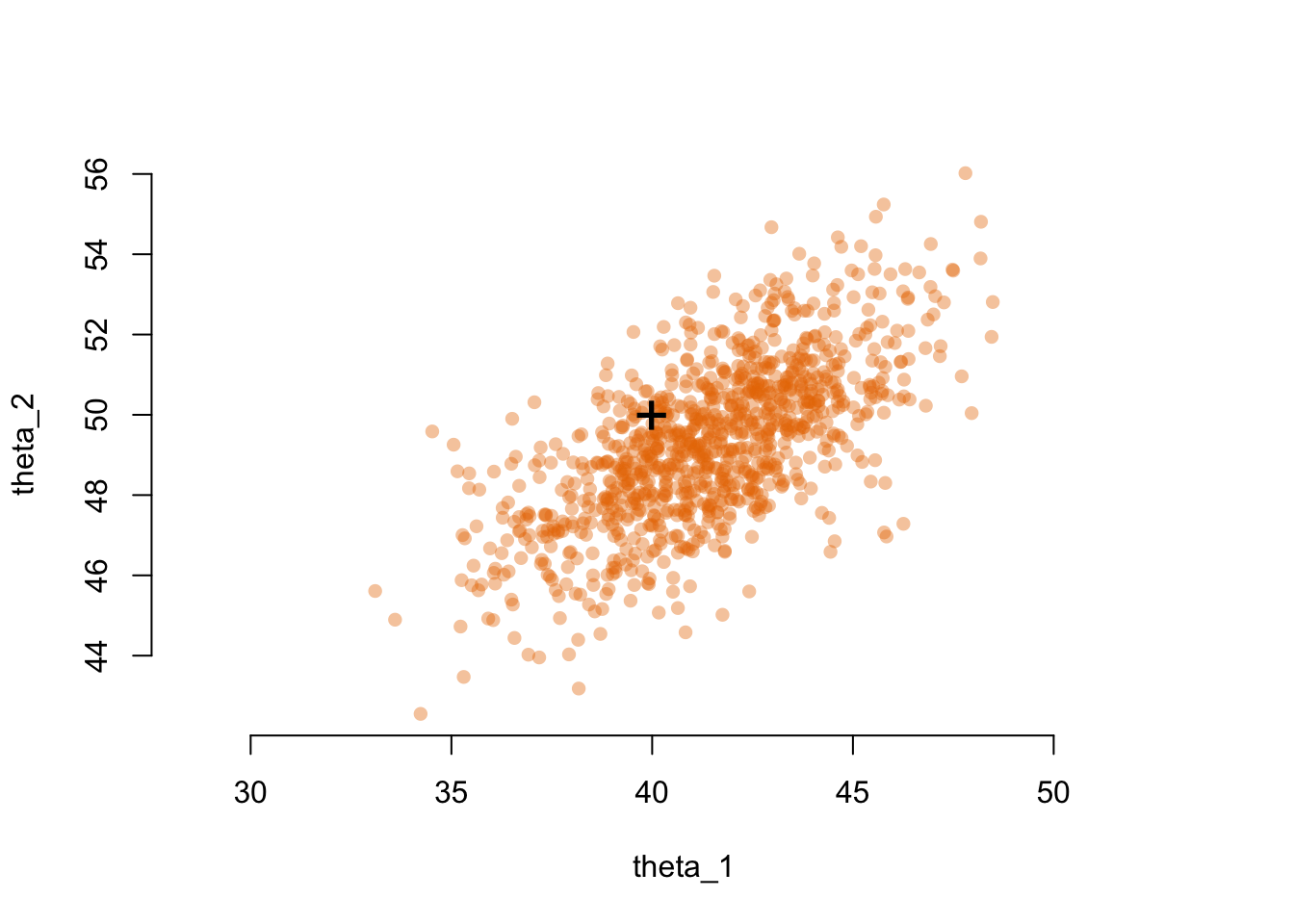
We can use this result to simulate 1000 values from the approximate sampling distribution of the MLE \(\hat\theta\). To do this, I will use a function from the {mgcv} package to draw samples from the corresponding multivariate Gaussian distribution.
mle_samples <- mgcv::rmvn(n =1000, mu = opt$par, V =solve(opt$hessian))plot( mle_samples,col =rgb(232/255, 120/255, 0, 0.4),xlab ="theta_1",ylab ="theta_2",asp =1,pch =16,bty ="n")points(x = theta_true[1], y = theta_true[2], pch ="+", cex =2)
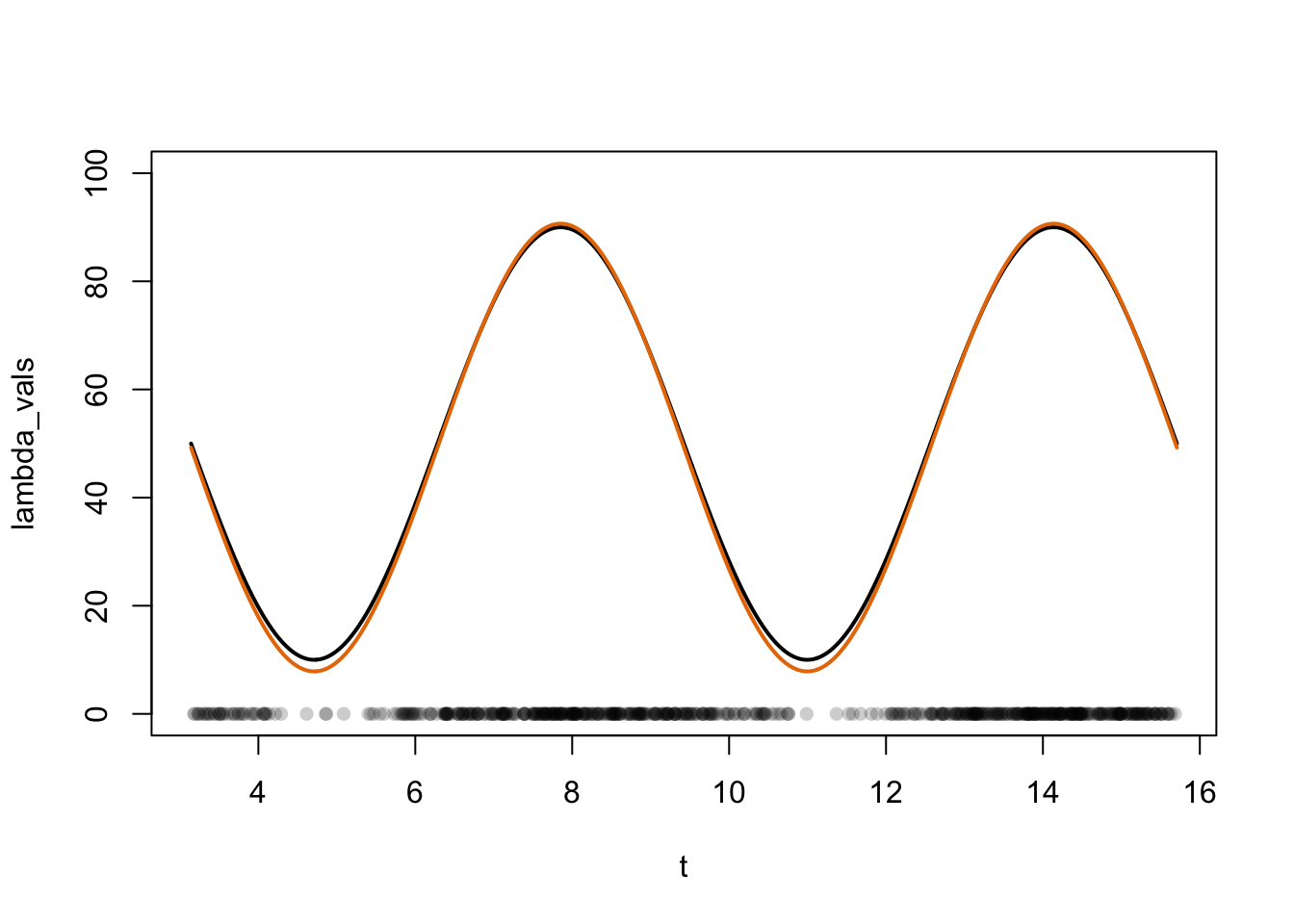
Finally, we can visualise the uncertainty in the estimated intensity by overlaying each of these curves
plot(x = t,y = lambda_vals, type ="l", ylab =expression("lambda(t)"),lwd =2, ylim =c(0,100), bty ="n") for (i in1:1000) {lines(x = t, y =lambda(mle_samples[i,], t),type ="l",lwd =2, col =rgb(232/255, 120/255, 0, 0.04) )}lines(x = t, y = lambda_vals, lwd =2) legend("topleft", legend =c("true", "estimated"), col =c("black", rgb(232/255, 120/255, 0, 0.4)), lwd =c(2,1), bty ="n")
Suggested Activity
Formally test whether a sinusoidal intensity improves the model fit over a HPP.
How does the length of the observation interval impact the power of this test?
Suggested Activity
Extend the code given to include a phase shift and phase compression
\[ \lambda(t;\theta) = a \sin(b t + c) + d.\]
Poster Ideas
Suggested Poster Topic
Pick your own \(\lambda(s;\theta)\) or \(\lambda(x;\theta)\) for simulation and inference.
How to compare different models \(\lambda_1(s;\theta)\) vs \(\lambda_2(s;\theta)\)?
Estimation when \(\Lambda(A;\theta)\) is an intractable integral.
Nonparametric (Kernel Density) estimation of \(\lambda(s;\theta)\).
How can we assess the goodness of fit of a point process model?
How can the idea of “residuals” be extended to point processes?
Simulation and Inference of Poisson cluster / simple inhibition processes.
Estimating the intensity of history-dependent processes using Expectation-Maximisation Algorithms.
Wrapping Up
That is all for today, make sure to have a go at the suggested activities in the second hour while I am around to help.
That is all of the technical content covered. Next session will be shorter, highlighting some applications and extensions of Poisson processes and giving general poster advice.
If you haven’t already, talk to me about your poster idea.